写在前面
带伙可以先看下腾讯的图,非常漂亮
再看看本文代码绘制的图,逼格降低99%
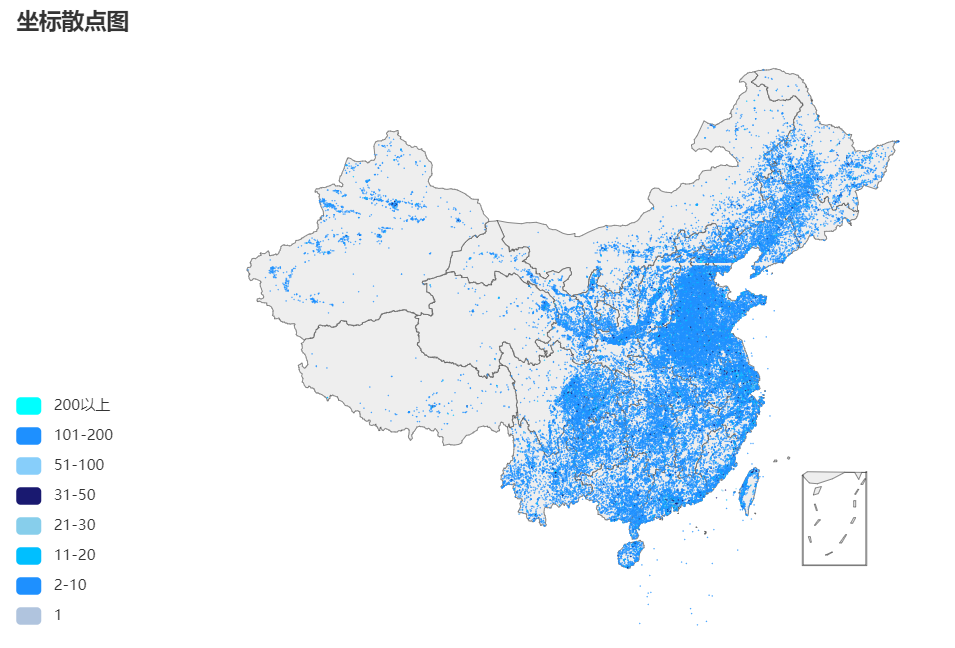
但是轮廓还是有的对吧!!!!话不多说,我们开始吧!
用到的包
import re
import requests
import json
from fake_useragent import UserAgent
import pandas as pd
import numpy as np
from shapely.geometry import Point
from shapely.geometry.polygon import Polygon
from pyecharts.ch