bs4解析网页
以爬取某网站表情包为例
用到的包
import requests
import re,os
from bs4 import BeautifulSoup as bs
URL地址
urls = ['https://www.doutula.com/search?type=photo&more=1&keyword=%E6%80%BC%E4%BA%BA&page={}'.format(i + 1) for i in range(50)]
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
处理网页
for i in range(len(urls)):
#利用requests读取网页数据
r = requests.get(urls[i],headers = headers)
#将网站转码
r.encoding = r.apparent_encoding
#如果返回值不是200说明遇到反爬了
if r.status_code == 200:
#保存网页数据
html = r.text
#调用bs4处理网页
bf = bs(html,'lxml')
print(bf)
else:
print('error')
#先分析第一页就够了
break
匹配图片地址和名称
观察‘print(bf)’返回的内容,我们使用以下命令:
#取保存图片地址和名称的div模块
html = bf.find('div',class_ = "random_picture")
#取图片地址
imgs = html.find_all('img',referrerpolicy="no-referrer")
#取名称所在字段
titles = html.find_all('p',style="display: none")
取图片格式并取精确的图片名
for j in range(len(imgs)):
try:
#匹配图片的格式(.jpg、.png、.gif等)
mat = str(imgs[j].get("data-original"))[-4:]
#如果是jpeg格式,就给它加上一个‘.’
if mat[0] != '.':
mat = '.' + mat
#图片的URL地址
path = imgs[j].get("data-original")
#print(path) #可以在这里输出看一下结果
#正则匹配,使图片名称更精确
pattern = re.compile('>.*?<')
#其实用search就可以
title = re.findall(pattern,str(titles[j]))[0][1:-1]
#现在就可以为图片命名了
filename = str(j) + title + mat
except Exception as e:
print(e)
#先练习第一张图片就可以
break
保存图片
with open('bqb/' + filename,'wb') as f:
f.write(img)
完整代码
去掉break,来爬取几千张怼人表情包吧!!
import requests
import re,os
from bs4 import BeautifulSoup as bs
urls = ['https://www.doutula.com/search?type=photo&more=1&keyword=%E6%80%BC%E4%BA%BA&page={}'.format(i + 1) for i in range(50)]
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
if not os.path.exists('bqb'):
os.mkdir('bqb')
for i in range(len(urls)):
r = requests.get(urls[i],headers = headers)
r.encoding = r.apparent_encoding
if r.status_code == 200:
html = r.text
bf = bs(html,'lxml')
html = bf.find('div',class_ = "random_picture")
imgs = html.find_all('img',referrerpolicy="no-referrer")
titles = html.find_all('p',style="display: none")
for j in range(len(imgs)):
try:
mat = str(imgs[j].get("data-original"))[-4:]
if mat[0] != '.':
mat = '.' + mat
path = imgs[j].get("data-original")
pattern = re.compile('>.*?<')
title = re.findall(pattern,str(titles[j]))[0][1:-1]
filename = str(j) + title + mat
img = requests.get(path,headers = headers).content
with open('bqb/' + filename,'wb') as f:
f.write(img)
except Exception as e:
print(e)
print('第' + str(i + 1) + '页下载完成')
else:
print('error')
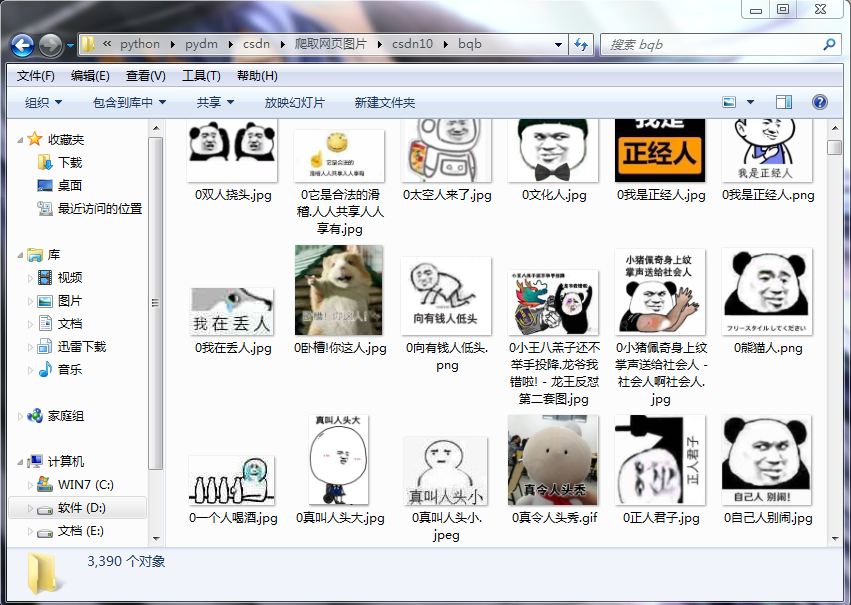
结果展示