写在前面
上篇文章写了用python训练验证码识别模型,精度还是蛮不错的,但是有个问题不知道各位看官有没有注意到,识别100张验证码用了10s,差不多0.1s/张,这个速度,看起来还是挺快的对吧,实话说一开始我也觉得他蛮快的,直到完成了C++的调用,识别100张验证码用了大概0.43s,吼吼,这是什么速度哇。
难点分析
为了实现这个api调用,至少花了我一整个星期的时间,目前网络上多数资料仍停留在tensorflow1.0版本的C++调用,还要下载源码编译出tensorflow.lib和tensorflow.dll,期间会遇到环境、网络等各种各样的问题,对于不经常接触这些的我实在不怎么友好,上次编译Linux内核费了老大劲了...
后来发现tensorflow提供了libtensorflow,包括CPU版本和GPU版本,下载后解压得到lib文件和dll文件,以及一些头文件,这就是本篇文章所使用的资源。
TensorFlow项目地址
获取资源:

环境
Windows 10Pro 64位
PyCharm 2021.2 Community
python3.8.5 64位
Visual Studio 2019 Community
OpenCV-4.5.2-vc14_vc15
模型处理
搜索libtensorflow相关资料后得知,它能读取的是savedmodel,之前我们保存的是hdf5文件,所以要做一些处理,这部分用python来完成
代码如下:
import tensorflow as tf
def hdf5tosaved():
file_path = './model.hdf5'
model = tf.keras.models.load_model(file_path)
model.save('./saved_model/h5tosaved', save_format='tf')
hdf5tosaved()
运行结果:

python调用savedmodel:
import tensorflow as tf
import numpy as np
import imutils
from imutils import paths
import cv2
import copy
import pickle
region = [(0, 0, 16, 25), (14, 0, 31, 25), (30, 0, 46, 25), (44, 0, 60, 25)]
MODEL_LABELS_FILENAME = "labels.dat"
CAPTCHA_IMAGE_FOLDER = "test"
captcha_image_files = list(paths.list_images(CAPTCHA_IMAGE_FOLDER))
captcha_image_files = np.random.choice(captcha_image_files, size=(total,), replace=False)
total = 100
true_count = 0
with open(MODEL_LABELS_FILENAME, "rb") as f:
lb = pickle.load(f)
f.close()
def resize_to_fit(image, width, height):
(h, w) = image.shape[:2]
if w > h:
image = imutils.resize(image, width=width)
else:
image = imutils.resize(image, height=height)
image = cv2.resize(image, (width, height))
return image
def savedmodel_infer(img=None, model=None):
result = model.predict(img)
return result
def main():
global true_count
model_path = "saved_model/h5tosaved"
model = tf.keras.models.load_model(model_path)
for image_file in captcha_image_files:
image = cv2.imread(image_file)
result = image_file.split('\\')[1].split('.')[0]
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
predictions = []
for reg in region:
letter_image = image[:, reg[0]:reg[2]]
letter_image = resize_to_fit(letter_image, 15, 25)
letter_image = np.expand_dims(letter_image, axis=2)
letter_image = np.expand_dims(letter_image, axis=0)
prediction = savedmodel_infer(letter_image,model)
letter = lb.inverse_transform(prediction)[0]
predictions.append(letter)
captcha_text = "".join(predictions)
if captcha_text == result:
print("RESULT is: {}, CAPTCHA text is: {}, True".format(result, captcha_text))
true_count += 1
else:
print("RESULT is: {}, CAPTCHA text is: {}, False".format(result, captcha_text))
main()
print("predict rate: ", true_count / total)
执行结果:

和hdf5文件的结果完全一致。
配置VS2019
新建C++空项目,右键属性,将opencv和tensorflow的相关路径添加进去
添加包含目录:

添加库目录:

ps:不要在意那个2.4.3,截止写文章时,github上面提供的是2.7.0版本,作者使用的也是2.7.0
添加链接器:

ps:如果使用Debug模式,附加依赖项是opencv_world452d.lib
另外,平台只能是x64,x86会报无法解析的外部符号
验证代码:
#include <stdio.h>
#include "tensorflow/c/c_api.h"
void version()
{
printf("This TensorFlow Version is %s.\n", TF_Version());
}
int main(int nargv,const char* argvs[]) {
version();
}
结果:

调用模型
需要先创建一个session,来调用之前转换的saved_model
不过创建session之前还有件事情要做,需要获取saved_model的tags、输入输出层等信息,用到的工具是saved_model_cli,这个工具在python的Scripts目录下,cmd中执行如下命令即可:
saved_model_cli show --dir h52saved --all
如果报错,请确认Scripts已添加至环境变量且python安装了tensorflow
获取到如下信息:
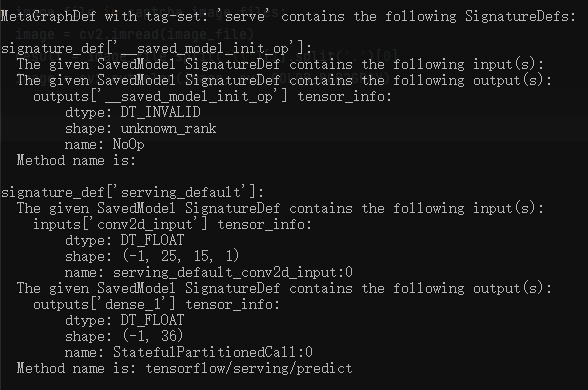
tag-set:serve
input:serving_default_conv2d_input:0
output: StatefulPartitionedCall:0
至此,所有准备工作均已完成。
创建session的代码如下:
#pragma warning (disable:4190)
#include <stdio.h>
#include "tensorflow/c/c_api.h"
#define PREDICT_ERROR 'A'
using namespace std;
TF_Graph* graph = TF_NewGraph();
TF_Status* status = TF_NewStatus();
TF_SessionOptions* session_opts = TF_NewSessionOptions();
TF_Buffer* run_opts = NULL;
const char* saved_model_dir = "saved_model/h5tosaved";
const char* tags = "serve";
int ntags = 1;
TF_Session* session;
// 调用这个函数,就成功创建了session
session = TF_LoadSessionFromSavedModel(session_opts, run_opts, saved_model_dir, &tags, ntags, graph, NULL, status);
图片处理
c++实现一个分割图片的函数:
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
cv::Mat split_img(cv::Mat img,int shape[]) {
// 创建一个指定shape的Mat,所有像素指定为(255,255,255)
cv::Mat region_img = cv::Mat(cv::Size(shape[1]- shape[0],25), CV_8UC3, cv::Scalar(255, 255, 255));
for (int i = 0; i < img.rows; i++) {
for (int j = shape[0]; j < shape[1]; j++) {
region_img.at<cv::Vec3b>(i, j - shape[0])[0] = img.at<cv::Vec3b>(i, j)[0];
region_img.at<cv::Vec3b>(i, j - shape[0])[1] = img.at<cv::Vec3b>(i, j)[1];
region_img.at<cv::Vec3b>(i, j - shape[0])[2] = img.at<cv::Vec3b>(i, j)[2];
}
}
return region_img;
}
其中的原理跟python差不多,遍历范围内的像素点。
至于转灰度和resize可以调用opencv的内置方法:
cvtColor(img_split, img_split, CV_BGR2GRAY);
cv::resize(img_split, img_split, cv::Size(15, 25));
完整代码
感觉拆开来看还是太麻烦了,直接上完整代码吧
#pragma warning (disable:4190)
#include <stdio.h>
#include "tensorflow/c/c_api.h"
#include <iostream>
#include <iterator>
#include <valarray>
#include <array>
#include <vector>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/imgproc/types_c.h>
#include <windows.h>
#include <io.h>
#define PREDICT_ERROR 'A'
using namespace std;
// 初始化TensorFlow
TF_Graph* graph = TF_NewGraph();
TF_Status* status = TF_NewStatus();
TF_SessionOptions* session_opts = TF_NewSessionOptions();
TF_Buffer* run_opts = NULL;
const char* saved_model_dir = "saved_model/h5tosaved";
const char* tags = "serve";
int ntags = 1;
TF_Session* session;
// 记录时间
clock_t start_time, end_time;
// 因为c++从二值化标签中获取源文本,所以要自定义一个数组
char letter[36] = {
'0','1','2','3','4','5','6','7','8','9','a','b',
'c','d','e','f','g','h','i','j','k','l','m','n',
'o','p','q','r','s','t','u','v','w','x','y','z'
};
// 分割图片的范围,一个二维数组,两个元素分别代表开始位置和结束位置
int region[4][2] = { {0,16},{14,31},{30,46},{44,60} };
// 打印tensorflow版本
void version()
{
printf("This TensorFlow Version is %s.\n", TF_Version());
}
// 这个函数用于创建TF_Tensor时的某个参数,说实话我完全不懂为什么这么写
static void DeallocateTensor(void* data, std::size_t, void*)
{
std::free(data);
#ifdef _DEBUG
std::cout << "Deallocate tensor" << std::endl;
#endif
}
// 这一段是主要的识别逻辑,参数是一个包含15*25个float类型数据的vector
char predict_letter(vector<float> vecs)
{
/*
验证模型是否加载成功,此处为了消除警告,我修改了TF_Code的声明
如果报错,修改为TF_GetCode(status) == TF_OK即可
*/
if (TF_GetCode(status) == TF_Code::TF_OK)
{
#ifdef _DEBUG
cout << "Load success!" << endl;
#endif
}
else
{
#ifdef _DEBUG
printf("%s\n", TF_Message(status));
#endif
return PREDICT_ERROR;
}
// 输入层的数量
int num_inputs = 1;
// 这里有个坑,input却要用TF_Output来声明..之前我不信邪,用TF_Input去声明,结果TF_SessionRun就报错了
TF_Output* input = (TF_Output*)malloc(sizeof(TF_Output) * num_inputs);
// serving_default_conv2d_input是之前获取到输入层名字,0就是冒号后面跟的数字
TF_Output in = { TF_GraphOperationByName(graph,"serving_default_conv2d_input"), 0 };
// 验证Graph是否获取成功
if (!in.oper) {
#ifdef _DEBUG
printf("load graph input error\n");
#endif
return PREDICT_ERROR;
}
else {
#ifdef _DEBUG
printf("load graph input ok\n");
#endif
}
input[0] = in;
// 输出层的数量,这一段跟上面没有什么差别
int num_outputs = 1;
// 申请内存
TF_Output* output = (TF_Output*)malloc(sizeof(TF_Output) * num_outputs);
// StatefulPartitionedCall是之前获取到的输出层名字,0是冒号后面的数字
TF_Output out = { TF_GraphOperationByName(graph,"StatefulPartitionedCall"), 0 };
// 验证Graph是否获取成功
if (!out.oper) {
#ifdef _DEBUG
printf("load graph output error\n");
#endif
return PREDICT_ERROR;
}
else {
#ifdef _DEBUG
printf("load graph output ok\n");
#endif
}
output[0] = out;
// 申请内存
TF_Tensor** input_values = (TF_Tensor**)malloc(sizeof(TF_Tensor*) * num_inputs);
TF_Tensor** output_values = (TF_Tensor**)malloc(sizeof(TF_Tensor*) * num_outputs);
// 创建指定大小的数组,这个要和输入层的shape对应
// 可能你注意到saved_model_cli输出的是(-1,25,15,1),但是这里不能写负数
const array<int64_t, 4> dims = { 1,25,15,1 } ;
// float变量的大小,用于申请内存
size_t size = sizeof(float);
// 1*25*15*1*size
for (auto i : dims) {
size *= abs(i);
}
// 申请一块内存,存放输入层的数据
auto data = static_cast<float*>(malloc(size));
// 将vecs中的数据拷贝给data
std::copy(vecs.begin(), vecs.end(),data);
/*
创建TF_Tensor,此处为了消除警告,我修改了TF_DataType的声明
如果报错,TF_DataType::TF_FLOAT修改为TF_FLOAT即可
*/
TF_Tensor* tensor = TF_NewTensor(TF_DataType::TF_FLOAT,
dims.data(),
static_cast<int>(dims.size()),
data,
size,
DeallocateTensor,
nullptr
);
// 验证TensorType是否为FLOAT类型
if (TF_TensorType(tensor) != TF_DataType::TF_FLOAT) {
#ifdef _DEBUG
cout << "Wrong tensor type" << endl;
#endif
return PREDICT_ERROR;
}
// 验证矩阵维度数是否相符
if (TF_NumDims(tensor) != dims.size())
{
#ifdef _DEBUG
cout << "Wrong number of dimensions" << endl;
#endif
return PREDICT_ERROR;
}
// 验证图片矩阵的尺寸是否相符
for (int i = 0; i < dims.size(); i++) {
if (TF_Dim(tensor, i) != dims[i]) {
#ifdef _DEBUG
cout << "Wrong dimensions size for dim: " << i << endl;
#endif
return PREDICT_ERROR;
}
}
// 根据tensor创建识别用的数据
auto tf_data = static_cast<float*>(TF_TensorData(tensor));
// 验证数据在流转过程中是否发生了变动
for (int i = 0; i < vecs.size(); i++) {
if (tf_data[i] != vecs[i]) {
#ifdef _DEBUG
cout << "Element: " << i << "does not match" << endl;
#endif
return PREDICT_ERROR;
}
}
// 输入层数据,看样子可以一次识别多个
input_values[0] = tensor;
// 调用TF_SessionRun,开始识别,识别结果保存到output_values中
TF_SessionRun(session, NULL, input, input_values, num_inputs, output, output_values, num_outputs, NULL, 0, NULL, status);
// 验证状态
if (TF_GetCode(status) == TF_Code::TF_OK)
{
#ifdef _DEBUG
printf("Session is OK\n");
#endif
}
else {
#ifdef _DEBUG
printf("%s\n", TF_Message(status));
#endif
return PREDICT_ERROR;
}
// 创建一个float集合用于保存识别结果
float* result = static_cast<float*>(TF_TensorData(output_values[0]));
// 保存result中最大值的索引
int max_location = 0;
// 保存result中的最大值
float max_value = 0.0;
// 通过一个简单的for循环获取最大值及其下标
// 如果有多个最大值,则取第一个的下标
for (int i = 0; i < 36; i++) {
if (result[i] > max_value) {
max_value = result[i];
max_location = i;
}
}
#ifdef _DEBUG
cout << max_value << endl;
cout << letter[max_location] << endl;
#endif
// 释放内存,这很重要!
free(input);
free(output);
free(input_values);
free(output_values);
free(tensor);
// 返回预测结果
return letter[max_location];
}
// 用于释放TF模型的内存
void freesession() {
TF_DeleteGraph(graph);
TF_DeleteSession(session, status);
TF_DeleteSessionOptions(session_opts);
TF_DeleteStatus(status);
}
// 用于分割图片
cv::Mat split_img(cv::Mat img,int shape[]) {
cv::Mat region_img = cv::Mat(cv::Size(shape[1]- shape[0],25), CV_8UC3, cv::Scalar(255, 255, 255));
for (int i = 0; i < img.rows; i++) {
for (int j = shape[0]; j < shape[1]; j++) {
region_img.at<cv::Vec3b>(i, j - shape[0])[0] = img.at<cv::Vec3b>(i, j)[0];
region_img.at<cv::Vec3b>(i, j - shape[0])[1] = img.at<cv::Vec3b>(i, j)[1];
region_img.at<cv::Vec3b>(i, j - shape[0])[2] = img.at<cv::Vec3b>(i, j)[2];
}
}
return region_img;
}
// 用于识别完整的验证码,参数为验证码的路径
string predict(const char* imgpath) {
// 声明两个Mat,一个用于读取验证码,一个用于存储分割后的字符图片
cv::Mat img,img_split;
img = cv::imread(imgpath);
// 用于保存预测结果
string result = "";
// 存储单通道像素点数据的集合
vector<float> temp = {};
for (int r = 0; r < 4; r++) {
// 每一次循环先清空temp中的数据
temp.clear();
// 切割图片的指定范围
img_split = split_img(img, region[r]);
// img_split转灰度,或许先把验证码整体转为灰度会更快一些,但是要重写分割函数
cvtColor(img_split, img_split, CV_BGR2GRAY);
// 调整图片尺寸
cv::resize(img_split, img_split, cv::Size(15, 25));
#ifdef _DEBUG
cout << "[" << img_split.cols << "," //宽度
<< img_split.rows << "]" << endl; //高度
cout << img_split.channels() << endl; //通道数
#endif
// 按顺序遍历img_split中的像素点,并将数据存入集合
for (int i = 0; i < img_split.rows; i++) {
for (int j = 0; j < img_split.cols; j++) {
int indexs = i * img_split.cols + j;
temp.push_back((float)img_split.data[indexs]);
}
}
// 调用上面的函数完成识别
result += predict_letter(temp);
}
// 验证是否遇到问题,如果结果字符串中出现了'A',说明一定是哪个环节出错了
if (result.find(PREDICT_ERROR) == result.npos) //没有找到PREDICT_ERROR
{
return result;
}
else
return "Error";
// 返回识别结果
return result;
}
// 主函数
int main(int nargv,const char* argvs[]) {
// 打印版本
version();
// 如果是在命令行执行,且传递了图片路径作为参数,则单独进行识别
if (nargv > 1) {
session = TF_LoadSessionFromSavedModel(session_opts, run_opts, saved_model_dir, &tags, ntags, graph, NULL, status);
string result = "";
result = predict(argvs[1]);
const char* test = result.c_str();
printf("%s\n", test);
}
// 否则,遍历目标文件夹下的所有png文件进行识别
else {
// 记录开始时间
start_time = clock();
// 记录识别正确的验证码数量
int true_count = 0;
// 加载模型
session = TF_LoadSessionFromSavedModel(session_opts, run_opts, saved_model_dir, &tags, ntags, graph, NULL, status);
// 遍历文件夹下的所有.png文件
std::string inPath = "test\\*.png";
// 用于查找的句柄
intptr_t handle;
struct _finddata_t fileinfo;
// 第一次查找
handle = _findfirst(inPath.c_str(), &fileinfo);
if (handle == -1)
return -1;
do
{
// 根据找到的文件名,补充图片路径(相对路径)
string filepath = "test/" + (string)fileinfo.name;
// 调用上面的函数完成识别
string result = predict(filepath.c_str());
// 打印识别结果
printf("RESULT is: %s, CAPTCHA text is: %s, ", result.c_str(), fileinfo.name);
if (filepath.find(result) != filepath.npos) {
true_count += 1;
printf("True\n");
}
else
printf("False\n");
} while (!_findnext(handle, &fileinfo));
// 关闭查找句柄
_findclose(handle);
// 记录结束时间
end_time = clock();
// 准确率
printf("predict rate: %f\n", (float)true_count / 100.0);
// 所用时间
printf("time: %fs\n", (float)(end_time - start_time) / CLOCKS_PER_SEC);
}
// 释放内存
freesession();
}
运行结果

同样是识别100张验证码,耗时仅为0.4s,我的天呐!相比python的11s,速度快了差不多28倍!
资源整理
暂无!因为dll文件过大,暂不提供,h5模型和验证集请移步上篇文章末尾获取。如果你需要dll文件,那就留言或者发邮件给我吧~我将尽力为您解决问题。
参考资料
知乎:怎样使用c/c++部署tensorflow2.0训练的模型?
CSDN:c++和opencv小知识:遍历图像像素的常用方法(详细,很全)
Github:Example TensorFlow C API
另附几条saved_model_cli命令:
# 查看tag_set
saved_model_cli show --dir <path_to_saved_model_folder>
# 查看SignatureDef key
saved_model_cli show --dir <path_to_saved_model_folder> --tag_set serve
# 查看输入输出层
saved_model_cli show --dir <path_to_saved_model_folder> --tag_set serve --signature_def serving_default
写在后面
目前还有32位不能调用64位DLL的问题,但是这个可以使用COM口组件解决,有空会写一篇相关的文章。
还有一个问题就是libtensorflow的Linux调用,这个也要等有时间再搞。